IMPORTANT NOTE
The 432 graphs displayed here are verification for last summer's heat index season, 1 May through 30 September. These graphs are provided as assessment tools, interpretation of them is the responsibility of the user. Past performance is not necessarily indicative of future performance.
Abstract
The heat index forecasts are verified against Rapid Update Cycle (RUC) hourly analyses of heat indexes computed from hourly 2-m temperature and dew point temperature analyses. Verification of the probabilistic forecasts is presented in terms of attribute diagrams complete with Brier score, Brier score decomposition, and Brier skill score values. The determinstic heat index forecasts are verified in terms of root-mean-squared (RMS) error and bias. The combined human and Global Forecast System (GFS) ensemble forecast shown on the forecast web page is compared with a similar forecast derived entirely from the NCEP global ensemble.
1. Introduction
There are two types of forecast products shown on the Weather Prediction Center (WPC) heat index forecast web page: 1) deterministic forecasts of actual heat index based on the WPC Medium Range (MEDR) Forecast Desk maximum and minimum temperature forecasts coupled with GFS ensemble derived dew point temperatures or National Digital Forecast Database (NDFD) forecasts (see next paragraph) and 2) probabilistic forecasts of heat index values exceeding certain threshold values. These two types of forecasts are made for the daily minimum heat index, daily mean heat index, and the daily maximum heat index. The results presented below give verification information for both types of forecasts for all three heat index parameters.
For the summer of 2007, significant changes were made to the heat index processing: The Day 3 forecasts are based on the National Digital Forecast Database (NDFD) grids. The days 4 through 7 forecasts are derived from the WPC 5-km resolution grid data products. The spatial resolution was improved from 40 to 20 km on the grid. The forecast uncertainty information still comes from the spread of the GFS ensemble, which is also upgraded over 2006. In light of the changes, the verification for 2006 or earlier should be applied cautiously to forecasts from 2007 onward. In general, model improvements will always influence the validity of verification from the previous summer.
It is useful to compare the verification of human-generated forecasts with forecasts based only on the model guidance without benefit of human intervention. To create model-only heat index products, the heat index forecast values derived from the human forecasts were omitted from the process, leaving only the GFS based ensemble mean as the deterministic forecast, and the deviations of the ensemble members from this mean as the basis for computing the standard deviation for calculating normally distributed probabilities.
In section 2 below, the use of the RUC hourly analyses is described. Section 3 describes the verification metrics and how to use the attribute diagrams. Section 4 presents the results by regions.
2. RUC Analysis
Hourly analyses of temperature and dew point temperature are available from the RUC system, which cycles continuously. Hourly analyses of heat index are computed from these analyses. The 24-h period used for computing the daily minimum, mean, and maximum is taken to be the 24 hours beginning at 0500 UTC and ending at 0400 UTC the following day. Over the continental United States, this time period allows the usual morning minimum and afternoon or evening maximum temperatures to fall in the same 24-h period, which would correspond to the day associated with forecast products. Once 24 analyses are available, one for each hour of the day as defined above, a daily average heat index at each grid point is computed. The daily minimum and maximum heat index values at each grid point are also determined from the hourly analyses. On completion of this process, an analysis of the daily minimum, mean, and maximum heat index exists to compare with forecasts for the particular valid day.
3. Verification Metrics
The verification of forecasts of the heat index parameters themselves (minimum, mean, and maximum) is presented in the terms of bias (mean error) and root-mean-squared (RMS) error. The bias expresses whether the forecasts are statistically too high or too low; hence, a perfect forecast has a zero bias. A forecast that is too warm has a positive bias, too cold, a negative bias. The RMS error gives a good indication of the overall error and is especially useful for comparing two forecast systems. RMS error is always positive with increasing values for increasingly worse forecasts; perfect forecasts have zero RMS error. The bias and RMS error values are shown as a function of forecast day for each heat index parameter and region. The title at the top of each figure gives the verifying date interval.
The verification for forecasts of the probability of each heat index parameter (minimum, mean, and maximum) exceeding a threshold value is presented in the form of an attribute diagram. The forecasts are categorized according to 10 non-overlapping equal-width ranges of forecast probability between 0 and 1, plus separate categories for 0 and 1. The observed frequency of the heat index parameter exceeding the given threshold is determined for each forecast probability category. On each attribute diagram, this observed frequency is plotted as a function of forecast category for both the MEDR desk and the model-only GFS ensemble forecast. Also drawn is a solid diagonal line showing a perfectly reliable forecast, for which the observed frequency always matches the forecast probability. The attribute diagram includes a set of histogram bars plotted with reference to the ordinate axis on the right side. These show the frequency of use of each forecast category by the forecasting source.
In addition to the perfect reliability reference line, three other reference lines appear on the attribute diagram. Two are drawn at the sample climatological frequency value on the abscissa and ordinate, oriented vertically and horizontally, respectively. The third is drawn through the intersection of the other two and lies half way between the horizontal climatological reference line and the perfect reliability reference line to the right of the aforementioned intersection. Points on reliability curves falling below this third line represent forecasts having no skill when those points are also to the right of the vertical reference line drawn at the sample climatological value on the abscissa.
Above each attribute diagram is a key showing the line types and colors used for the reliability curves and frequency of forecast use histogram bars. Also included in the keys above the figure are the Brier score values (lower scores are better) for both the human forecast and the model-only GFS ensemble. The Brier score is decomposed into three useful values: 1) reliability, which quantifies the error in the probability over the categories conditional on the forecasts; 2) resolution, which measures how well the categories conditional on the forecasts exhibit observed frequencies that differ from the sample climatology; and 3) uncertainty, which quantifies the random variability of the observations. These values are shown in the keys for the reliability curves. The Brier score is equal to reliability minus resolution plus uncertainty as indicated in the keys. The resolution term and the reliability term are both zero in the case of forecasting the climatological frequency only, resulting in a Brier score equal to the uncertainty term. Thus, to have a good (low) Brier score it is not sufficient to have good (low) values for the reliability term, but also good (high) values for the resolution term, which is subtracted.
To see an explanatory attribute diagram with animated anotations, click here. The animation is silent. (Thanks to Andrew Loughe for creating this animated figure from a PowerPoint slide.)
The Brier skill score value is given in the keys for the use frequency histogram. It is computed by subtracting the ratio of the Brier score to the sample climatological Brier score from one. A perfect probabilistic forecast has a Brier skill score equal to exactly one. A Brier skill score less than zero means that the forecast is worse than predicting the sample climatological value all of the time.
The figure title above the key gives the projection day, the heat index parameter, the threshold, the region abbreviation, and the verifying date range.
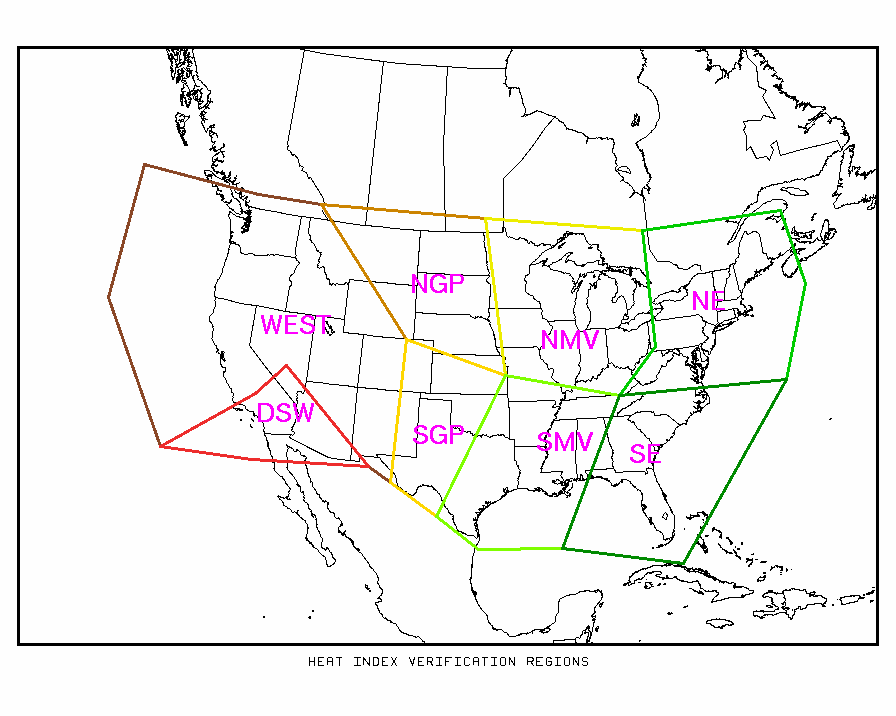
The verification is done separately for each region shown on the map below. Because severe heat is not as common from the Pacific coast across the Great Basin and Rocky Mountains, that entire area is combined into one region designated WEST. The very hot, but usually dry, desert southwest is a separate region. To see verification results for a particular region, click on the string of letters denoting the region on the map below. To see verification over the entire US, click on the links displayed below the map.